

資料抄寫引擎(Replication Engine)
資料儲存庫(Datastore)與抄寫引擎實例(Instance):資料儲存庫代表欲連結的資料庫系統。在安裝軟體的過程中,首要步驟就是選擇資料儲存庫的類型,例如:IBM Db2、Microsoft SQL Server 或 Oracle Database 等資料庫管理系統。軟體安裝完成後,可以根據需求建立一個或多個執行實例,分別連結至不同的資料庫。每個執行實例將作為獨立的執行程序運行,負責處理來源與目標資料庫之間的資料同步抄寫,或是同時扮演來源與目標系統的角色,處理雙向資料同步的抄寫作業。
組態資料表(Metadata):每個抄寫引擎實例都會擁有一組用於記錄資料庫連線、資料表對應(Mappings)、抄寫訂閱工作(Subscriptions)以及事件通知(Notifications)等相關設定的組態資料表。這些資料表預設會建立在來源與目標資料儲存庫中,共計三個以〝TS〞開頭的資料表,分別是:TS_AUTH、TS_BOOKMARK 和 TS_CONFAUD。
來源擷取與目標抄寫引擎(Source Capture Engine & Target Engine):每個抄寫引擎實例會根據其扮演的角色,配置 Source Capture Engine 和 Target Engine。前者負責擷取來源系統的資料異動,後者則將這些異動套用於目標系統。抄寫引擎中的 Refresh Reader 負責讀取資料表的歷史資料,以便讓 Apply Agent 執行從來源資料表到目標資料表的初始化資料同步。Log Reader 則負責讀取資料庫日誌(Transaction Logs),以便於讓 Apply Agent 可以執行資料異動交易的同步,將變更從來源資料表傳送到目標資料表。
資料轉換引擎(Transformation Engine):在來源與目標系統進行資料同步抄寫的過程中,資料轉換引擎負責處理資料表欄位與內容過濾、格式與編碼轉換,以及衝突偵測等相關工作。
存取伺服器(Access Server)

管理主控台(Management Console)



鏡映(Mirror)
重新整理(Refresh)
IDR 支援的來源系統(Source Databases)
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 11 / 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 11 / 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Oracle Enterprise Linux 8
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 11 / 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
| 品牌/家族 | 軟體名稱 | 版本 | 作業系統 |
|---|---|---|---|
| IBM Db2 for Linux, UNIX and Windows (LUW) | DB2 Enterprise Server Edition | 11.1.0、11.5.0.0、11.5.8.0、11.5.9.0、12.1 |
|
| DB2 Workgroup Server Edition | 11.1.0 | ||
| Db2 Advanced Workgroup Server Edition | 11.1.0、11.5.0.0 | ||
| Db2 Developer-C | 11.5.0.0 | ||
| DB2 Direct Advanced Edition | 11.1.0 | ||
| DB2 Direct Standard Edition | 11.1.0 | ||
| Db2 Advanced Enterprise Server Edition | 11.1.0、11.5.0.0、11.5.8.0、11.5.9.0、12.1 | ||
| IBM Db2 Warehouse | Db2 Warehouse on Cloud | Continuous Delivery | N/A |
| Db2 Warehouse | 11.5.4.0、11.5.6.0、11.5.7.0、11.5.8.0 |
|
|
| IBM Integrated Analytics System | 1.0 | ||
| IBM dashDB Local | 1.0 | ||
| IBM Db2 for i | IBM Db2 for i5/OS | 7.2、7.4 | IBM Power Systems |
| IBM Db2 for z/OS | IBM Db2 for z/OS | 12.1、13.1.0 | IBM Mainframe |
| IMS & VSAM | IBM z/OS | N/A | IBM Mainframe |
| Informix | Informix Dynamic Server Enterprise Edition | 12.10、14.10、14.10.xC2、14.10.xC3 |
|
| Microsoft SQL Server | Microsoft SQL Server Enterprise Edition | 2016、2017、2019、2022 |
|
| Microsoft SQL Server Standard Edition | 2016、2017、2019、2022 | ||
| Microsoft Azure SQL Database | N/A | N/A | |
| MariaDB | MariaDB Enterprise | 10.4 |
|
| MySQL | MySQL | 5.6、5.7、8.0 |
|
| Oracle | Oracle Database | 23ai |
|
| Oracle Database 12c Release 2 Enterprise Edition | 12.2 | ||
| Oracle Database 12c Release 2 Standard Edition | 12.2 | ||
| Oracle Database 18c Enterprise Edition | 18.3 | ||
| Oracle Database 19c | All Versions | ||
| PostgreSQL | PostgreSQL | 12.0、13、14.0、15、16.0 |
|
| Amazon RDS for PostgreSQL | N/A | N/A | |
| Amazon Aurora PostgreSQL | N/A | N/A | |
| Azure Database for PostgreSQL | N/A | N/A | |
| Sybase | Sybase Adaptive Server Enterprise | 15.5、15.7、16.0 |
|
IDR 支援的目標系統(Target Databases and Applications)
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 11 / 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 11 / 12 / 15
- Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Confluent Platform 3.0+
- Cloudera Distribution of Apache Kafka v2.1.0
- Hortonworks Data Platform (HDP) v2.5
- IBM BigInsights v4.3
- IBM Event Streams for IBM Cloud (formerly Message Hub)
- IBM Event Stream for IBM Cloud (version 2018.3.1+)
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 11 / 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- AIX 7.2 / 7.3
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
- Windows Server 2012 / 2012 R2 / 2016 / 2019 / 2022 / 2025
- CentOS 7(7.1~7.9) / 8(8.1~8.3-2011)
- Red Hat Enterprise Linux 7(7.1, 7.5) / 8(8.1)
- SUSE Linux Enterprise Server 12 / 15
| 品牌/家族 | 軟體名稱 | 版本 | 作業系統 |
|---|---|---|---|
| Apache Hadoop | Apache Hadoop | 2.2.0 |
|
| Cloudera CDH | 5.0、6.0 | ||
| Hortonworks HDP | 2.4 | ||
| Apache Kafka | Apache Kafka | 0.10.0.0、1.0.0、2.0.0 |
|
|
IDR for Kafka 使用 Apache Kafka 3.5.1 Client 進行連線,並相容於以下商業發行版:
|
|||
| Amazon Redshift | Amazon Redshift | N/A | N/A |
| Event Server | Sun Java Message Service Specification | 1.1 |
|
| CockroachDB | CockroachDB | 23 |
|
| PostgreSQL | EnterpriseDB Postgres Advanced Server | 12.0、13、14.0、15、16.0 |
|
| Google BigQuery | Google BigQuery | N/A | N/A |
| IBM Cloudant | IBM Cloudant | N/A | N/A |
| IBM InfoSphere DataStage | IBM InfoSphere DataStage (IBM InfoSphere Information Server) | 9.1、11.3、11.5、11.7 |
|
| IBM Netezza | IBM Netezza Cartridge for IBM Cloud Pak for Data | 11.0 |
|
| SingleStore DB | SingleStore DB | 7.8、8.0 |
|
| Snowflake | Snowflake | N/A | N/A |
| Teradata | Teradata | 16、16.10、16.20、17、17.10 |
|
| YugabyteDB | YugabyteDB | v2.14、v2.16、v2.17 |
|
資料轉換功能(Transformational capabilities)
- 不同欄位名稱的對應。
- 不同資料型別的轉換。
- 修改欄位的資料長度。
- 指定欄位抄寫的預設值。
- 關聯資料表進行合併。
- 使用包含 IF / THEN / ELSE 邏輯判斷的資料轉換操作。
- 透過衍生表達式(Derived Expressions)建立新欄位。
- 執行客製化資料轉換程式碼(User Exits 功能)。
- 欄位轉換函數(Column Functions)
字串函數(String functions):用於處理文字型字串,例如字串串接(Concatenation)、子字串提取(Substring)、去除字串開頭與結尾的空白(Trimming)等操作。
日期時間函數(Date and time functions):專門處理日期與時間格式的資料,像是取得當前日期、將日期與時間欄位合併為一個 Timestamp 欄位等功能。
轉換函數(Conversion functions):用於不同資料型別之間的轉換,例如將 Character、Numeric、Date 等型別的資料進行相互轉換。
條件與變數函數(Conditional and variable functions):提供靈活的邏輯運算能力。例如,使用 %IF 函數進行表達式判斷並根據條件返回不同結果;使用 %VAR 函數來宣告新變數並為其指定值,或檢索已存在變數的值。
資料函數(Data functions):在同步抄寫過程中對資料值進行特別處理,例如使用 %BEFORE 函數可強制將資料恢復至異動前的值。
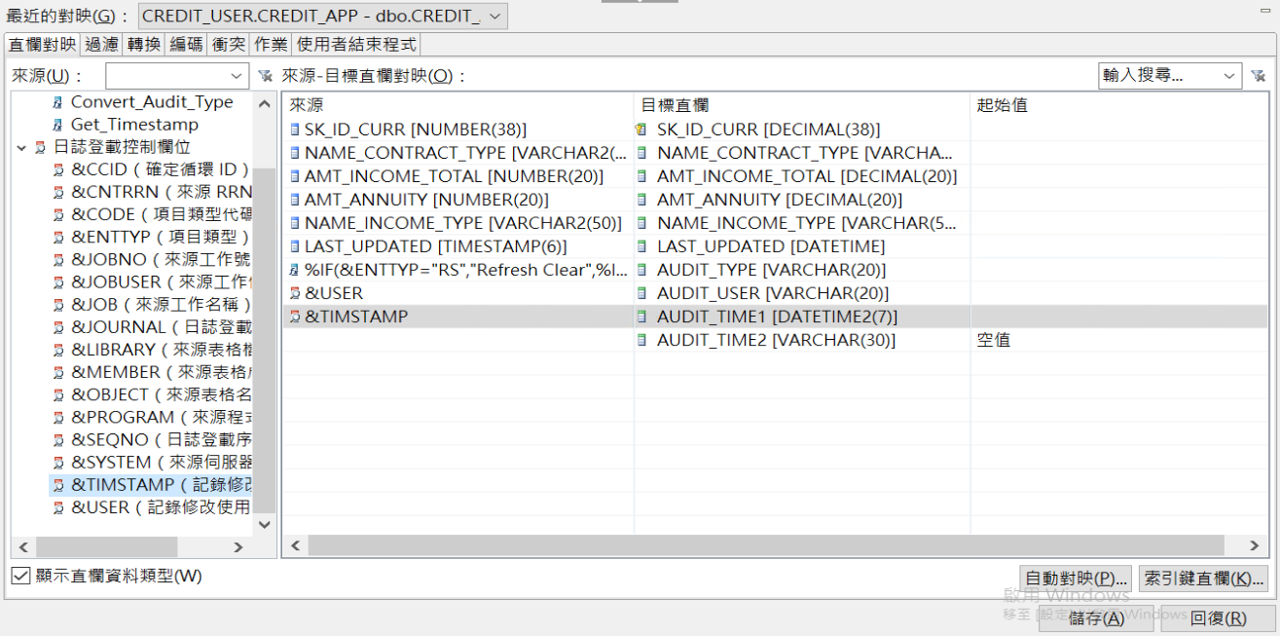
- 日誌控制欄位(Journal Control Fields)
直接對應到目標系統的欄位,例如:&TIMESTAMP 代表異動時間、&USER 代表異動人員、&CCID 代表 Commit Cycle ID。
進行資料行層級(Row level)資料過濾,用來識別需要包含或排除的日誌條目,例如:&JOB = 'PURGE001'。
結合衍生表達式(Derived Expressions)進行 IF / THEN / ELSE 邏輯判斷的資料轉換操作,例如:%IF(%SYSTEM = 'USHDQR', 'Atlanta', 'Toronto')。
- 關聯資料表(Table Joining)
當 IDR 同步抄寫交易資料表時(僅包含產品代碼欄位),透過 %GETCOL 函數從產品資料表中取得對應的產品名稱,並將產品代碼及產品名稱一併傳送至目標資料庫。
若透過指定鍵值從產品資料表中找出超過一筆以上的產品名稱,則 %GETCOL 函數會傳回第一筆找到的產品名稱;如果未能找到任何產品名稱,則會傳回指定的預設值。
在使用 %GETCOL 函數關聯產品資料表時,使用者可以同時取得多個欄位值,例如:產品名稱、產品規格、產品包裝等。
- User Exit 功能
Table-level User Exits:在指定資料表發生資料庫異動事件之前或之後,執行一組自定義操作。
Subscription-level User Exits:在指定訂閱(Subscription)發生資料庫 Commit 事件之前或之後,執行一組自定義操作。
資料抄寫方法(Replication modes)
- 重新整理(Refresh)
標準重新整理(Standard Refresh)
將來源資料表中的完整資料副本傳送到目標資料表,通常用於資料同步的初始化階段。差異重新整理(Differential Refresh)
基於來源與目標資料表之間的差異來更新目標資料表。與 Standard Refresh 不同,Differential Refresh 不會清除目標資料表中既有的資料,而是逐一比對來源與目標資料表中的每筆資料,找出缺漏、變更或新增的資料並進行同步。差異重新整理可以選擇以下三種模式:僅重新整理(Refresh Only):針對目標資料表與來源資料表之間的差異部分進行同步更新。
重新整理並記錄差異(Refresh and Log Differences):除了進行差異重新整理外,IDR 還會在目標抄寫引擎的 Metadata 中建立一個 Log table,用於記錄同步過程中的操作。
僅記錄差異(Only Log Differences):這個模式僅建立 Log table,並不會實際執行資料同步更新。它主要用於識別來源資料表和目標資料表之間的所有差異。使用這個模式可以先評估資料表之間的差異,並在隨後決定是否進行資料同步更新。
列子集重新整理(Subset Refresh)
此模式主要透過 SQL 語句中的 WHERE 子句,根據指定的過濾條件,對資料進行細緻化的標準或差異重新整理操作。要執行 Subset Refresh,需要在資料同步抄寫時配置資料表擷取點(Table Capture Point),或在訂閱(Subscription)中設置擷取點(Scraping Point)。這樣便可以精確地篩選需要同步的資料子集,提升同步效率與精確度。- 鏡映(Mirror)
連續鏡映(Continuous Mirroring)
連續鏡映啟動後,IDR 會以不中斷的方式進行來源與目標系統之間的資料異動即時同步。欲停止連續鏡映同步抄寫,可以在管理主控台中針對選定的訂閱(Subscription)執行「結束抄寫」功能。啟動結束抄寫功能,可以選擇以下四種結束抄寫方法:
啟動結束抄寫功能,可選擇以下四種結束抄寫的方法:正常結束(Normal):待目前正在進行的同步抄寫工作完成後停止連續鏡映抄寫。因此,這個選項需要一些時間來確認同步抄寫工作已達到穩定並可結束的狀態。
立即結束(Immediate):立即停止所有正在進行的同步抄寫工作,然後結束連續鏡映抄寫工作。
中止抄寫(Abort):立即停止所有正在進行的同步抄寫工作,然後快速結束連續鏡映抄寫工作。此選項是結束抄寫工作最快的方法。
預定結束(Scheduled End):IDR 會處理資料庫交易日誌中所有已 Commit 的變更,然後以正常方式結束同步抄寫工作。此選項可以指定「立即」、「特定日期和時間」以及「特定日誌位置」作為結束同步抄寫工作的時機。
預定結束(Scheduled End)
「預定結束」與「連續鏡映」的唯一區別在於,使用者可以在啟動同步抄寫工作之前決定結束抄寫的時機點。例如,當系統管理人員不希望應用系統在尖峰使用期間因同步抄寫工作影響效能時,可以透過設定「特定日期和時間」選項,讓 IDR 在預定的時間自動停止同步抄寫工作。資料過濾功能(Row & Column level filtering)
- 資料行過濾(Row level filtering)
1 = 1:此表達式始終傳回 True 值。
(SALES < 10000) OR (SALES > 90000):需使用括號將同一欄位變數的布林表達式進行分組。請注意,表達式不支援 SALES < 10000 OR > 90000 這樣的寫法。
NOT((AIRPORT = ‘ATL’) OR (AIRPORT = ‘CLT‘)):判斷式的分組順序需要明確以括號進行區隔。請注意,表達式不支援 NOT(AIRPORT = 'ATL' OR 'CLT‘) 這樣的寫法。
%RTRIM(DEPT) = ‘IT‘:欄位轉換函數(Column Functions)可應用於表達式中的任何運算子。
PRINCIPAL *(1 + INTRATE) > 20000:表達式中可使用四則運算。
%IF(COUNTRY = ‘US’, PRICE, PRICE * 1.2) > 50:由於 %IF 函數無法傳回布林結果,因此必須將 %IF 函數的回傳值與表達式中的另一個值進行比較。
STATE IN (‘CA’, ‘AZ’, ‘AL’, ‘GA’, ‘CT‘):IN 運算子是一個 SQL SELECT WHERE 子句中有效的語法。
&JOB = ‘QTRPURGE‘:日誌控制欄位(Journal Control Fields)可用於識別特定交易日誌的資訊。在此範例中,&JOB 用於識別特定的工作,接著可以決定要包含或省略與該工作相關的資料記錄。
- 資料表欄位過濾(Column level filtering)
目標資料表只需要來源資料表 150 個欄位中的 20 個欄位。因此,若僅選擇所需的 20 個欄位,可以大幅減少同步到目標資料表的資料量,從而節省網路頻寬和處理資源。
來源資料表包含使用者 ID 和個人薪資等機密資訊。如果目標資料表不需要這些資料,則可以將這些欄位排除在資料同步抄寫的範圍之外。
對映套用類型(Apply methods)
- 標準模式(Standard)
在應用系統移轉或升級的平行測試期間,為了確保舊系統與新系統能夠使用相同的資料,可以透過 Standard 模式在兩個資料庫之間即時同步資料。
為實現應用程式讀寫分離架構,降低資料查詢或產製報表對應用程式資源的耗用,可以透過 Standard 模式將所需資料即時同步到另一個資料庫。
- 稽核模式(LiveAudit)
基於法規或監管要求,需要保留所有與資料相關的操作稽核軌跡記錄。
對資料庫中敏感資料異動的稽核軌跡進行追蹤和記錄。
向下游應用程式提供來源資料處理的操作資訊。例如,ETL 應用程式可以利用時間戳記值來確定應處理哪些異動操作,從而確保目標系統的資料與特定時間點保持一致。
- 調適性套用模式(Adaptive Apply)
當某個外部應用程式獨立於來源資料表修改目標資料表內容時。
當使用者希望從資料庫交易日誌中還原訂閱資料表的內容時,可以透過將日誌位置設定為特定起點或時間點,並使用 Adaptive Apply 模式來填入空的目標資料表,確保其包含最新的資料。
- 彙總模式(Summarization)
- 資料行合併(Row Consolidation)
一對一合併(Consolidation One to One)
在此模式下,IDR 允許我們將分散在不同來源資料表中的共用實體資料(例如業務人員、客戶或產品)合併到目標資料表的一筆資料中。一對多合併(Consolidation One to Many)
此模式允許我們將來自查找表(Lookup Table)的資料異動套用到受影響的所有目標資料表。由於來源查找表上的一筆異動可能會影響到多筆目標資料表中的資料,透過此模式,除了保持目標資料表與主來源資料表的一致性外,還能確保目標系統中的各個輔助資料表與來源資料表的變更保持同步。- 衝突偵測和解決方法(Conflict detection and resolution)
在目標資料表中新增(Insert)一筆鍵值重複的資料(此操作違反單一鍵值的限制)。
在目標資料表中修改(Update)一筆鍵值不存在的資料。
在進行資料修改(Update)之前,來源資料表和目標資料表中該筆資料的內容不一致。
在目標資料表中刪除(Delete)一筆鍵值不存在的資料。
在進行資料刪除(Delete)之前,來源資料表和目標資料表中的該筆資料內容不一致。
來源系統獲勝(Source Wins):以來源系統的資料覆蓋目標系統,如果目標系統不存在該筆資料,則新增(Insert)該筆資料。這個作法有助於保持來源資料表和目標資料表之間的一致性。
目標系統獲勝(Target Wins):丟棄來源系統的該筆異動資料,保持目標系統的資料完整性。
以最大值為優先(Largest Value Wins):根據該筆資料中某個欄位的最大值來決定使用來源系統或目標系統的資料。例如,來源系統的時間戳記相較目標系統更新,則使用來源系統的資料覆蓋目標系統。由於空值(Null)會被視為最小值,因此若目標系統中不存在該筆資料,則來源系統的資料會被插入。如果來源與目標系統的欄位值相同,IDR 會採用「目標系統獲勝(Target Wins)」作法來解決衝突,即保持目標系統的資料不變。
以最小值為優先(Smallest Value Wins):根據該筆資料中某個欄位的最小值來決定使用來源系統或目標系統的資料。如果目標系統中不存在該筆資料,IDR 將使用空值(Null)作為最小值,並且不會在目標系統插入該筆資料。
使用 User Exit 回傳的結果:IDR 根據使用者自定義的邏輯來解決資料衝突,並將 User Exit 回傳的結果套用於目標資料表。




沒有留言:
張貼留言