對於資料科學家而言,定義和建立「分析的單位 (Unit of analysis)」是一件重要的工作。簡單來說,這指的是在進行分析時,一筆資料代表什麼才能讓分析有意義。假設專案的分析目的是預測哪些客戶可能會接受促銷方案,那麼預測模型可能需要每一筆都是不同的客戶而非不同的交易;換個角度,如果分析目的是識別購買演唱會門票的欺詐行為,那麼模型可能需要的是每一筆交易的樣本資料。
因此,當我們確定預測分析目的之後,接下來就得仔細觀察原始資料的結構與內容,除了必要的資料清理處理之外,有時候也需要重塑資料的結構。例如,我們需要分析客戶層面的問題,那麼就需要從客戶歷史交易記錄、購買行為與互動記錄中找出一個方法將多筆資料進行彙整,並將它們表示為每個人的單一筆資料 (Single record)。在本篇文章中,我們將介紹「相異的」、「聚集」、「設成旗標」這三個常用於重塑資料結構的節點,同時我們也會連帶介紹統計圖中的「Web」節點,並使用它來分析資料與資料之間的關聯性。
1.相異的節點(Distinct)
無效字元:取代為 @ 字元。
編碼:UTF-8。
單引號:納入為文字。
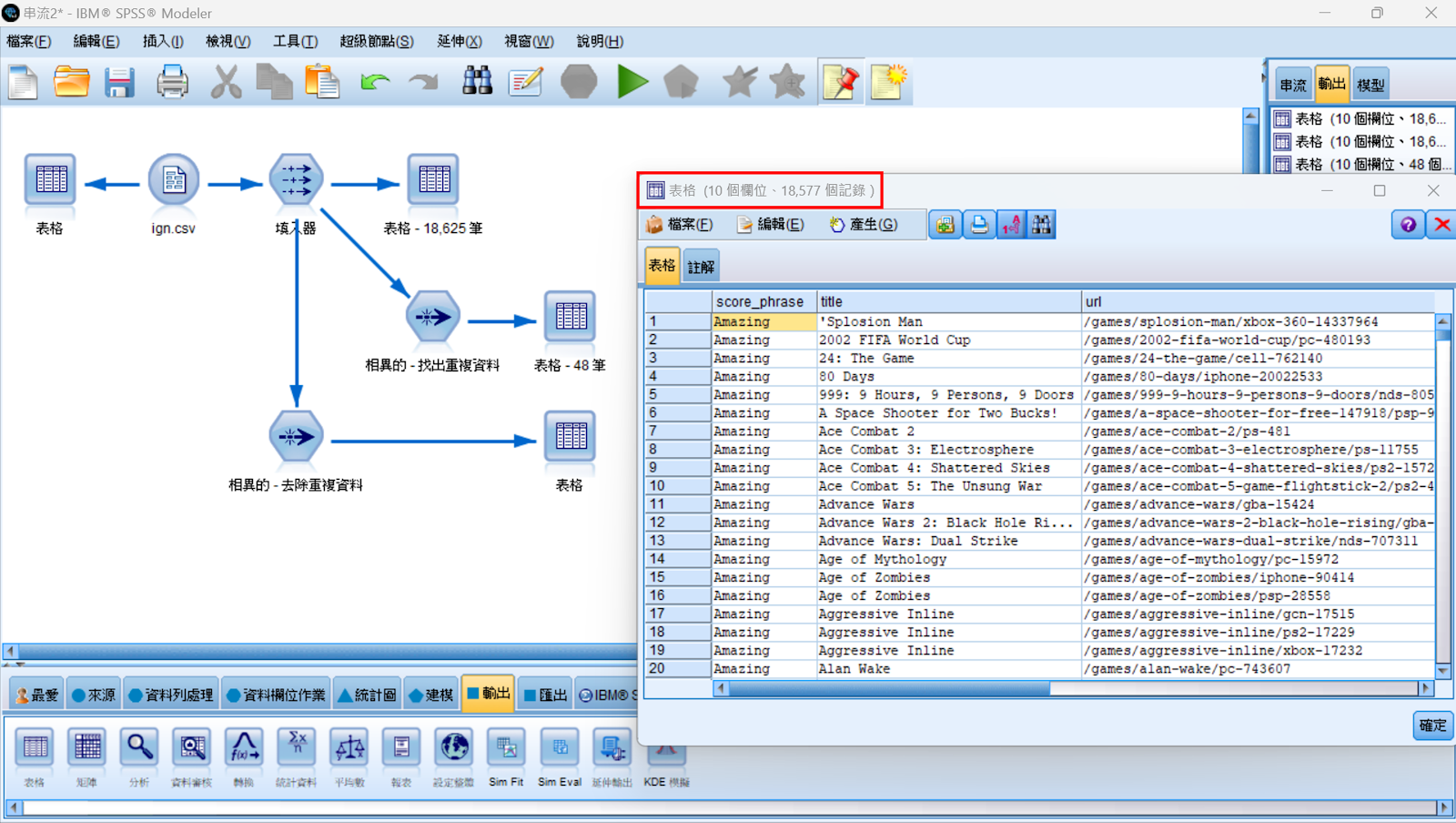
將 ign.csv 輸出為資料表後,可以觀察到這個資料集共有 18,625 筆資料。此外,SPSS Modeler 產生四筆異常資料的警示,這正是上個步驟我們將無效字元取代為 “@” 的原因。
仔細觀察這四個無效字元在字串中出現的位置,初步判斷是英文的 ' 符號。因此,我們可以在 ign.csv 節點後方鏈結一個「填入器」節點,將 title 欄位中出現的 ?@ 字元置換為 ' 符號。請參考以下的選項配置:
填入欄位:title。
置換:基於條件。
條件:issubstring("?@",@FIELD)。
取代成:replace("?@","'",@FIELD)。
完成了簡單的資料清理後,我們要開始使用「相異的」節點快速找出重複的資料。將「資料列處理」工具箱中的「相異的」節點鏈結在「填入器」節點後方。在設定視窗中,「模式」選擇:僅棄置每個群組的第一個記錄;「分組的索引鍵欄位」選擇:全部的欄位。
「相異的」節點共提供三種 Distinct 的模式:
為每一個群組建立複合記錄(Create a composite record for each group):這個模式會為重複的資料建立一筆複合的記錄(Composite record),假設我們有兩筆相同客戶編號的客戶基本資料,則可透過這個模式將這二筆資料進行合成,並選擇保留最初為新客戶收集的基本資料。啟用該模式後,可使用「複合」頁籤進行進階設定。
僅包含每個群組的第一個記錄(Include only the first record in each group):這個模式會刪除所有重複的資料,只保留第一次出現的資料。若選擇對所有欄位進行重複比對時,此模式可以快速過濾掉重複資料並建立一個乾淨的資料集。
僅棄置每個群組的第一個記錄(Discard only the first record in each group):這個模式會刪除重複資料中第一次出現的該筆資料並保留後續重複的資料,這對於檢查哪些是重複的資料很有幫助。
使用「表格」節點檢視重複資料的清單,我們可以觀察到這個資料集共有 48 筆完全重複的資料。
接下來,我們同樣使用「相異的」節點將這 48 筆重複資料去除,建立一個乾淨的資料集。我們可以直接複製貼上之前的「相異的」節點,完成鏈結後開啟設定視窗,將「模式」改成:僅包含每個群組的第一個記錄,其餘設定不變。
使用「表格」節點檢視去除重複資料後的清單,我們可以觀察到資料集共包含 18,577 筆不重複的資料。
找出重複資料或是去除重複資料只是重塑資料的第一步,儘管這項操作應該可以算在資料清理的範圍內,但透過 SPSS Modeler 視覺化的操作介面,這些過去繁瑣的工作也都變得相對輕鬆。「相異的」節點除了可以快速找出差異的資料之外,還可以指定分組內的資料排序規則,有關 SPSS Modeler「相異的」節點的詳細說明,請參閱官方文件:差異節點。
2.聚集節點(Aggregate)
資料彙總是一項常見的資料準備任務,彙總是一種縮減多筆資料的方法,讓資料可以依據指定欄位進行分組,並對選定的欄位進行摘要處理,例如計算總和或平均值等。我們可以使用 SPSS Modeler 的「聚集」節點來調整資料集,讓每一筆資料不再代表客戶在一年內購買的個別商品交易明細,而是代表在一年內的平均交易金額和總交易金額。
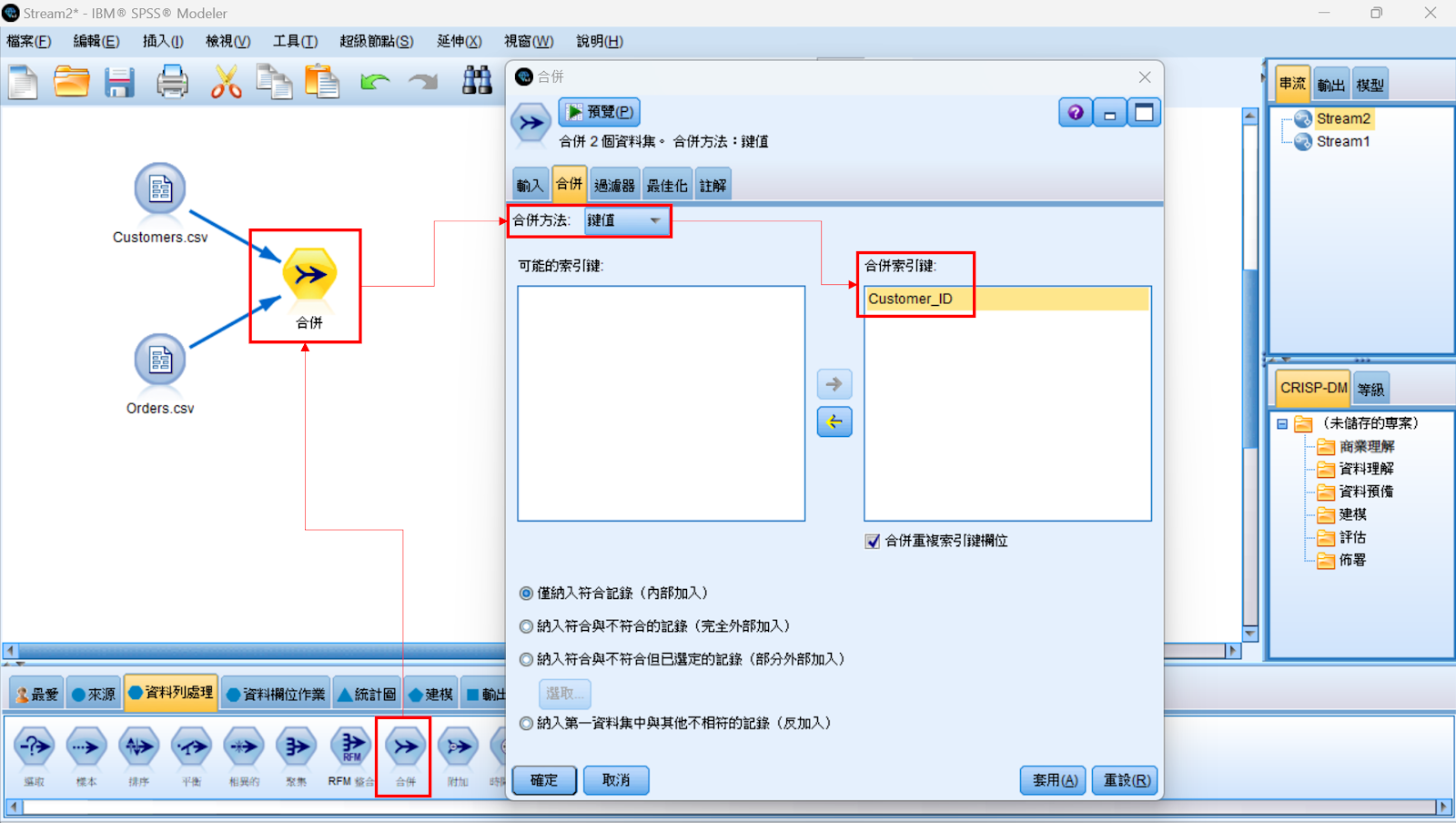
接下來我們會使用「合併」節點將 Customers.csv 與 Orders.csv 資料來源檔透過共用鍵值 Customer_ID 合併為單一資料集。接著再使用 Customer_ID 進行資料聚集,產生每個客戶的首次交易日期、最近交易日期、訂單總金額以及平均訂單金額等摘要欄位。使用「變數檔案」節點載入這二個檔案時,請留意以下三項設定(紅框標記):
編碼:UTF-8。
單引號:納入為文字。
雙引號:配對並捨棄。
從「資料列處理」工具箱中把「合併」節點加入至串流畫布中,將二個 CSV 檔案鏈結到「合併」節點。在設定視窗中,「合併方法」選擇:鍵值;「合併索引鍵」指定為:Customer_ID。
將合併後的結果輸出為資料表,我們可以觀察到這個合併後的資料集共有 9,426 筆資料。這是一個非常典型的客戶交易明細資料表,我們將使用它進行「聚集」節點的實際應用。
從「資料列處理」工具箱中把「聚集」節點加入至串流畫布中,將「合併」節點鏈結到「聚集」節點,開啟設定視窗,「索引鍵欄位」指定:Customer_ID 與 Customer_Name。「索引鍵欄位」是選擇彙總分組欄位的地方,它允許我們指定按照什麼方式來進行彙總。鍵值欄位通常是一種識別碼,例如客戶 ID、商店編號或產品代碼,它也可以表示特定事件,例如交易編號或日期時間戳記等。我們可以指定多個鍵值欄位,而它會依據我們指定的順序建立一個分組的層次結構。例如,我們將商店編號和交易月份作為鍵值欄位,在此條件下,若我們有 10 家商店在過去一年間的交易資料,則最終的彙總資料集將由 120 筆資料組成。
完成鍵值欄位的設定後,在「基本聚集」區段中,將 Order_Date 與 Sales 加入到「聚集欄位」中。接著指定這二個欄位的聚集方式,Order_Date 勾選:最小值與最大值,用來表示這個客戶的首次交易日期與最近交易日期;Sales 則勾選:總和與平均數,代表這個客戶的訂單總金額以及訂單平均金額;最後,勾選「包含欄位中的記錄計數」,這可以用來代表訂單交易筆數。
有關「聚集」節點的設定配置說明如下:
聚集欄位:這是我們指定要彙總的欄位和選擇彙總摘要方法的地方。例如,我們可能希望計算每位客戶所有交易訂購金額的合計值。此外,我們可能還希望計算客戶每次下訂單時平均消費的金額。如果資料集包含日期欄位,我們可以選擇「最小值」和「最大值」,它們分別代表第一次和最近一次購買的日期。
預設模式:大部分情況下,資料科學家希望使用多種方法對多個變數進行摘要計算。我們可以在這裡設定預設的方法,而無需逐一為每個變數設定摘要的方法。
包含欄位中的記錄計數:彙總的目的是希望可以依據鍵值欄位指定的分組層次進行多筆資料的總結摘要。勾選「包含欄位中的記錄計數」會自動建立一個欄位,這個欄位可以告訴我們總共彙總了多少筆資料來形成每個鍵值欄位的彙總摘要資料。
聚集表示式:聚集表示式功能僅支援包含資料庫連線節點的串流,它能夠對聚集分組的多筆資料進行客製化的彙整摘要,例如兩個日期時間欄位之間的時間差平均值,或是一個欄位的最大值與另一個欄位的最小值之間的差異。有關 SPSS Modeler 聚集表示式的詳細說明,請參閱官方文件:聚集表示式。
將彙總後的結果輸出為資料表,我們可以觀察到資料集縮減到 2,703 筆資料。從這個彙總表中可以了解每位客戶首次交易日期、最近交易日期、訂單總金額、平均訂單金額等數據,最後一個欄位則表示交易筆數。
從資料庫行銷的角度思考,就目前彙整的資料中已經可以知道客戶首次交易日期、最近交易日期、訂單總金額、平均訂單金額、以及交易筆數等重要資訊,如果我們還想知道客戶交易頻率的平均值(平均間隔幾天下單),同樣也可以透過 SPSS Modeler 輕鬆地實現。接下來我們另外建立一個分支串流,請在「合併」節點後方鏈結一個「過濾器」節點,選擇 Customer_ID、Customer_Name、Order_Date、Sales 這四個欄位向後面的節點傳送資料。
由於我們後續將使用自訂公式的方式計算每一筆交易日期之間的間隔天數,因此需要先讓資料集依據客戶編號與訂購日期進行排序。請於「過濾器」節點後方鏈結「排序」節點,排序方式依序選擇 Customer_ID 與 Order_Date(遞增排序)。
接著在「排序」節點後方鏈結「導出」節點,指定導出欄位名稱為:Frequency_by_Days;導出為:公式;欄位類型:預設值;下方公式編輯器欄位請輸入:if Customer_ID = @OFFSET(Customer_ID, 1) then date_days_difference(@OFFSET(Order_Date, 1), Order_Date) else 0 endif。
複製貼上之前的「聚集」節點,將它與「導出」節點鏈結,開啟設定視窗並於「聚集」欄位新增 Frequency_by_Days,聚集方式勾選:平均數。
最後在「聚集」節點後方鏈結「表格」節點,執行這個分支串流即可看到我們期望的結果。
「聚集」節點對於重塑資料來說非常實用,通常我們可以依據實際分析的需求將資料集進行分組與彙整,若以顧客消費行為分析為例,後面可以再鏈結「RFM 分析」節點或是鏈結「Web」節點進行消費關聯性分析。有關 SPSS Modeler 聚集節點的詳細說明,請參閱官方文件:「聚集」節點。
3.設成旗標節點(Set to Flag)
在 SPSS Modeler 中,類別型變數(Categorical Variables)有時被稱為集合欄位(Set fields),例如客戶交易明細資料表中「產品類別」欄位包含了 ”家具”、 ”科技產品” 與 “辦公用品” 等三種分類。若因資料分析需求,需要知道客戶是否購買這三種產品,我們可以透過「設成旗標」節點快速建立三個新的旗標欄位來滿足這個需求。
我們繼續從「聚集」節點的串流接著下去,請在「合併」節點後方鏈結「類型」節點,依據下圖完成對所有欄位的「量測層次」以及「角色」的設定。請注意:設定完成後要點擊「讀取值」按鈕,完成實例化的動作(值域內容解析)。
請於「類型」節點後方鏈結「資料欄位作業」工具箱中的「設成旗標」節點,在設定視窗中,「集合欄位」選擇:Product_Category,下方的「可用的設定值」區塊會顯示產品分類包含的所有項目,包含 ”家具”、 ”科技產品” 與 “辦公用品” ,選取這三個產品分類點擊向右箭頭,將它們加入到右方的「建立旗標欄位」區塊。
集合欄位:這裡可以指定要用來建立旗標變數的類別型欄位。特別需要注意,「設成旗標」節點是一個需要資料完全實例化的節點之一,如果資料尚未完全實例化,則「集合欄位」下拉選單中不會顯示任何可用內容。
可用的設定值:如果類別型欄位已完全實例化,則「設成旗標」節點會從上游的「類型」節點中取得所有的類別值並顯示在清單中。
建立旗標欄位:這裡會列出「設成旗標」節點將建立旗標欄位(Flag fields)的類別值。
接著是代表旗標欄位真值與偽值的符號,請使用預設的 T 與 F 即可,最後的「整合鍵值」區塊依序加入:Customer_ID 與 Customer_Name 這二個欄位,我們將以它們作為資料彙總的分組依據。
將彙總後的結果輸出為資料表,我們就可以快速地知道每個客戶是否曾經購買過這三種類別的產品。
4.Web 節點
Web 節點(或稱為網路圖節點)主要用來顯示兩個或兩個以上旗標欄位(或類別型欄位)值之間關係的緊密程度,網路圖使用不同粗細程度的線條來顯示關聯性與關聯的緊密程度。我們可以在「設成旗標」節點後方鏈結「統計圖」工具箱中的「Web」節點,在設定視窗中,將 ”家具”、 ”科技產品” 與 “辦公用品” 這三個已設成旗標的產品分類加入到「欄位」區塊中。勾選「僅顯示真旗標」,「線的值為」選擇:整體百分比,其餘選項均使用預設值。
執行「Web」節點的分支串流,可以從輸出視窗中觀察到,接近 40% 的客戶同時購買科技產品與辦公用品,超過 35% 的客戶同時購買家具與辦公用品,左圖中的線條粗細代表了二個產品分類之間的關聯強度。
接下來我們可以試著分析產品子分類之間的購買關聯性,請於「類型」節點後方鏈結一個新的「設成旗標」節點,在設定視窗中,「集合欄位」選擇:Product_Sub-Category,下方的「可用的設定值」區塊會顯示產品子分類包含的所有項目,請選取全部的產品子分類,點擊向右箭頭,將它們加入到右方的「建立旗標欄位」區塊。最後的「整合鍵值」區塊依序加入:Customer_ID 與 Customer_Name 這二個欄位,我們同樣將以它們作為資料彙總的分組依據。
請於「設成旗標」節點後方鏈結一個新的的「Web」節點,在設定視窗中,將所有已設成旗標的產品子分類加入到「欄位」區塊中。勾選「僅顯示真旗標」,「線的值為」選擇:絕對,其餘選項均使用預設值。
執行這個新的「Web」節點的分支串流,請開啟並切換至右方的「控制項」面板,我們先調整一下圖形呈現的視覺效果。請於「Web 顯示」點選:大小顯示強/正常/弱;「強連結高於」設定為:300;「弱連結低於」設定為:150。這是一個主觀的設定,我們主要是希望讓強連結顯示為較粗的線條,正常連結則顯示為細線條,弱連結則以虛線表示。網路圖下方尺規是資料過濾功能,按照我們的設定,關聯性強度介於 100 ~ 400 才會顯示在圖形中。從網路圖的線條粗細可以清楚發現 ”紙類” 與圖中的其他四類產品有較強烈的關聯性。
切換到「摘要」面板,從明細表格中可以透過詳細的數值對產品間的訂購關聯性有更清楚的理解。明細表包含強、中、弱關聯的詳細統計資訊。
除了分析產品子分類之間的購買關聯性,我們也可以分析客戶分類與產品子分類之間的關係,也就是了解那些客戶族群會喜歡那些產品類型。這一次我們直接在「類型」節點後方鏈結一個新的「Web」節點,請將 Customer_Segment 與 Product_Sub-Category 加入到「欄位」區塊中,不要勾選「僅顯示真旗標」,「線的值為」選擇:絕對,其餘選項均使用預設值。
執行這個新的「Web」節點的分支串流,首先可以先依據喜好調整強弱連結的臨界值,接著點擊上方「Web」按鈕將網路圖切換為「方向配置」。從下圖中可以清楚觀察到,四種不同分類的客戶對於產品的喜好(關聯強度)。
「Web」節點非常適合用來以視覺化方式分析資料彼此之間的關聯性與強度,從上面二個例子中我們可以知道,除了旗標型欄位之外,我們也可以分析類別型欄位之間的關聯強度。在實務上,我們可以先透過網路圖進行關聯性的視覺化分析,接著就可以使用關聯規則演算法建立商品推薦模型,這種應用在電子商務型業務中非常普遍。有關 SPSS Modeler「Web」節點的詳細說明,請參閱官方文件:Web 節點。
版權聲明
文章內容未經授權,請勿進行任何形式的複製、修改或發佈本文內容,如需轉載或引用,請在使用時注明出處並取得授權。本文中提及的特定公司、產品、品牌名稱等僅為描述目的,其版權歸屬於相應的公司或擁有者。






























沒有留言:
張貼留言